It's been more than 5 years since we founded Motiva. What we do fundamentally has been the same; helping companies send the most useful messages to the right people at the most convenient time. In this post, I'd like to discuss workflow orchestration and why I wish I'd known about it earlier.
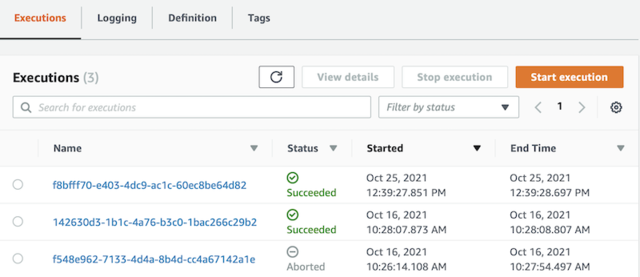
Here's a screenshot of one of our workflow execution histories (an execution = a specific workflow run). Not only is there status information to each step, but we also have a record of the input and output for every step. This granular tracking is valuable for diagnosis and the high-level visibility makes designing complex workflows managerable. We process hundreds of executions per hour and each execution handles up to a couple millions of small decisions by interacting with internal and external systems.
Let's run through the evolution of our Process Batch workflow from the beginning to illustrate how we got to this point, using a sample of the typical kind of job we regularly perform at Motiva.
The task is to send certain emails to particular email addresses (contacts).
We aren't MailChimp though. One of our product's selling points is that our machine learning can determine the most useful* messages for the right people. Thus, identifying which particular emails to send to whom and at what time is the real work of this Process Batch workflow.
We query our machine-learning engine to map the "most likely useful" asset to each target. This defines what needs to be done for each batch.
From the list of email addresses, we need to:
- know when to send to each contact
- know which email variation to send to each contact
- send out all the emails accordingly
Typically, this list of email addresses are contacts that either signed up for a particular newsletter or registered for a particular product. Thus, they are contacts with a history of engaging with our clients; providing a history of data for our machine-learning models to optimize on... but that's another story.
This Process Batch workflow comprises 3 activities:
- scheduler -- enables you to do something at a specific time
- asset picker -- chooses the email to be sent for each individual
- sending out the emails
Quick and dirty first version
We built our first system in a few weeks as a service-oriented architecture. The system includes an email Campaign Orchestrator service, a Machine-Learning service, and an Email-Sender service, which all communicate via HTTP. I added a cron job onto our server to ping the Campaign Orchestrator service every few minutes. On receiving this heartbeat ping, the Campaign Orchestrator service would query our database table of schedules and create batches ready to be sent.
Here's a sequence diagram of the interactions between the services for this Process Batch workflow.
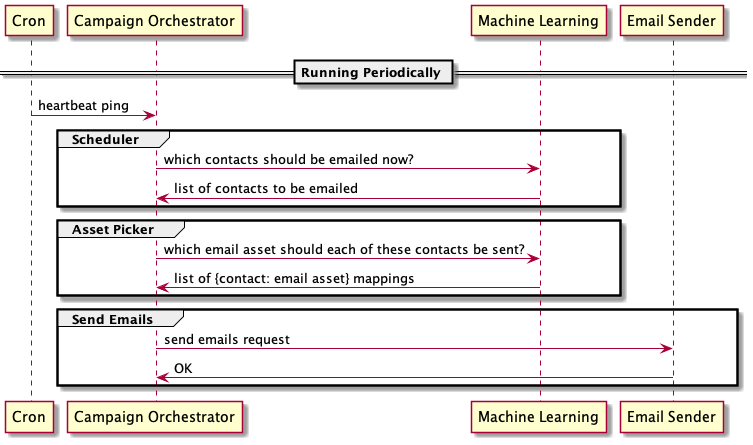
This 2016 version didn't last long though. The biggest problem was that since actions were performed in an impromptu manner, we had no observability when things weren't working for any reason. To diagnose which branch of logic a workflow took, I had to match our logs with database records to step through logical forks one by one. It was a slow and tedious chore. We had many basic reliability issues in our early days. I still recall having to debug a production problem after a few drinks around Christmas time while my CEO and one of our clients was waiting on the line -- a stressful experience that I gave a talk on last year.
Materialize batches for observability
Naturally, the improvement needed was to materialize all the impromptu events as database records ahead of time and determine everything beforehand. It meant, for example, that instead of doing a query of the system at each time interval, working out what needs to be done and processing the batch on the spot, we do all that at the beginning of a campaign once and for all. What this translates to in terms of easier diagnostic is that we can query our database for what decision was made at any point of interest in a workflow. It's a deterministic system that goes straight for the win.
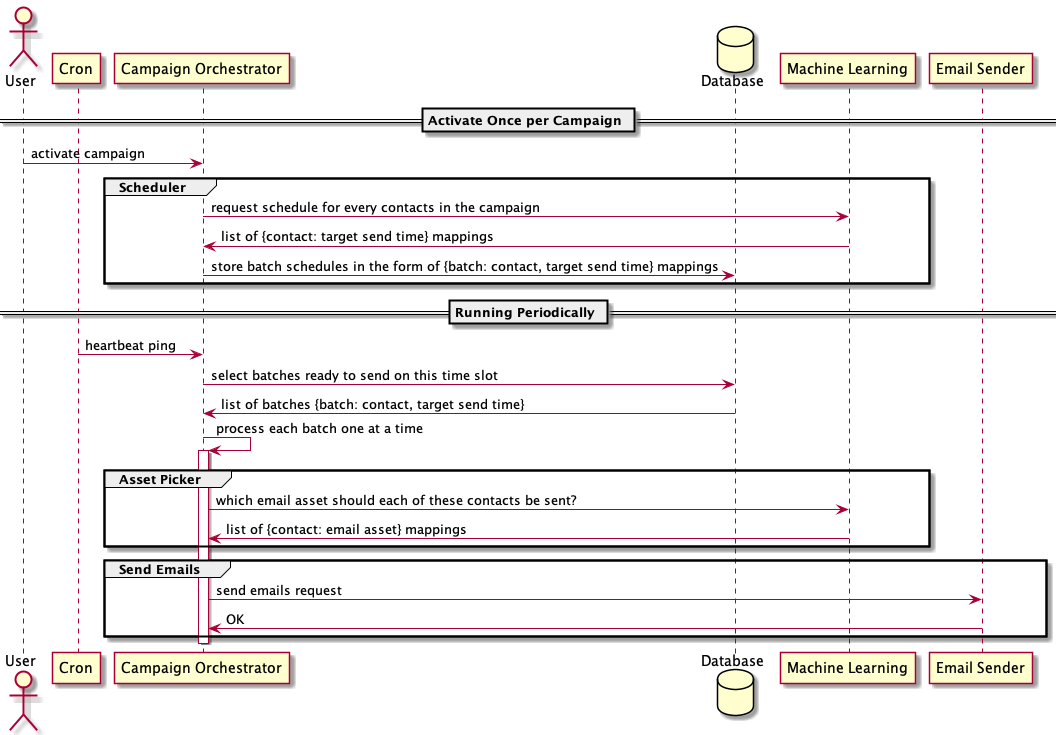
There are two major changes to this second version.
- we moved the scheduler out of the Process Batch workflow to run only once per campaign
- all campaign batches are determined and materialized in advance
In this scenario, our Process Batch workflow has split into two workflows. The first part is the Activation workflow, which happens once and only once when the user finishes configuring a campaign. During this Activation workflow, the Campaign Orchestrator assign send-time schedules to every contacts; for example, Contact A should be emailed at 9am and Contact B should be emailed at 3pm.
Our Process Batch v2 workflow is still regularly triggered by a cron job. But instead of needing to determine which batches to send impromptu, we simply query our database for these pre-scheduled batches that are ready to be sent.
This second version lasted a few more months. But as our product was getting more use from our customers, we needed to scale the workflow. Particularly as some batches could take many minutes to process, whereas others would take only seconds. We needed a way to ensure that all batches get processed in reasonable time.
Message-based architecture for scaling
We chose to add a queue to our Process Batch workflow in order to choreograph batch worker allocation. Each Process Batch request was created as an independent message and put into the Process This Batch queue. When we needed to process a batch, we sent a Process Batch message with the required data to the queue. To respond to these messages in the queue, we had N number of deployed workers in the Campaign Orchestrator service subscribing to the queue.
That's a lot of words. Perhaps it's easier with a diagram. Note the addition of the Process This Batch queue.
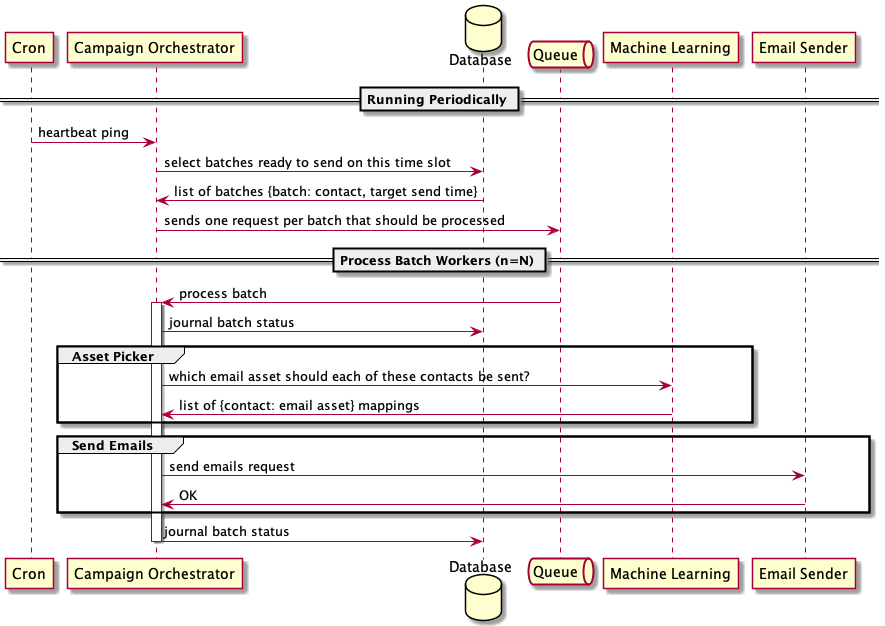
Scaling
Scaling was simply a matter of deploying more workers to increase the N value. Luckily, we kept our components and services decoupled, so scaling was easy. Additional benefits from placing our Process Batch workflow in a queue were:
- failure handling
- high-level observability
Failure handling
In the previous v2 version of this workflow, we needed to explicitly scan our database for failed batches in order to recover them. With this queue-based v3 workflow, the corresponding message for a failed batch was simply not acknowledged and the message would automatically be put back into the queue to be processed again. The big caveat here is that batches need to be idempotent so that processing the same batch more than once doesn't cause any unexpected behaviour.
Observability
With Process Batch requests going through an actual queue within our infrastructure (as opposed to an in-process queue), we achieved high-level monitoring. We configured various alarms in our queue metrics (i.e., CloudWatch alarms on AWS SQS metrics) such as "age of oldest message in the queue in a 5-min period", "number of messages sent in a period", and "number of messages received in a period". Such alarms provided an overview of the health of our Process Batch queue, and by extension, the health of our Process Batch workflow. These metrics replaced a few database queries that we used to run to get similar data.
Meanwhile, as the demand for our product grew, we scaled our other workflows by using this setup and created numerous queues in the process. Over the following couple of years, we moved to an entirely message-based architecture. Below is our extended Process Batch v3.1 workflow where the intra-system calls -- both to the Machine-Learner and the Email Sender -- were communicated through their own respective queues.
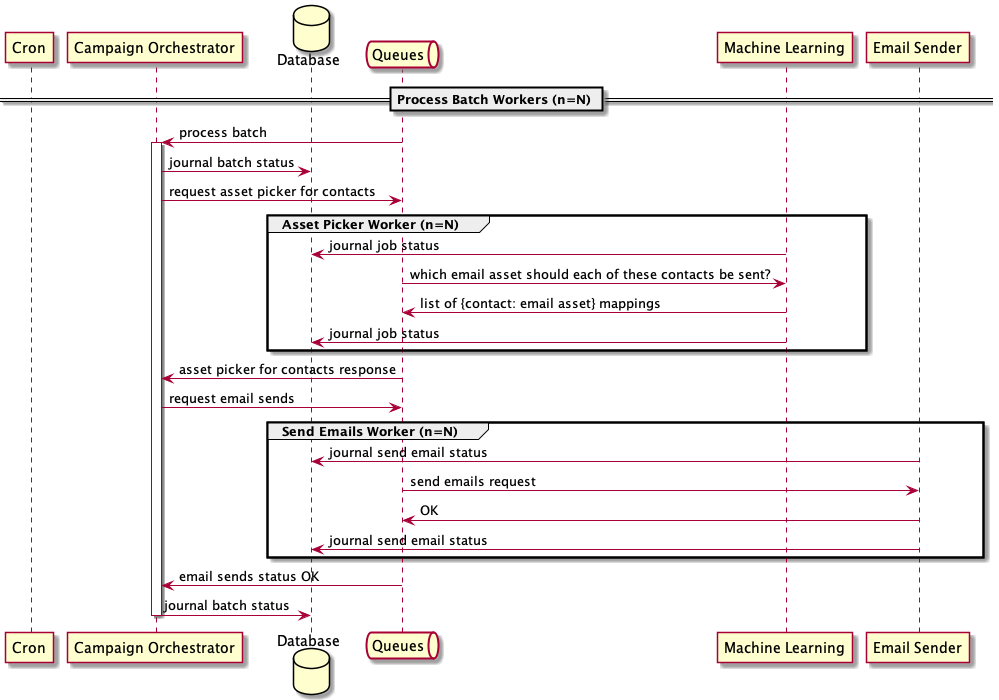
The database journal writes for each worker constitute a small but significant addition to the above graph. What's shown here is a simplistic illustration. This database action could mean writing actual database journal records to log job status, or more often, the transactional reversion of database writes if a job fails. These actions are important because we spent a lot of time accounting for steps failing in different parts of a workflow. Keeping track of each step facilities easier diagnostics.
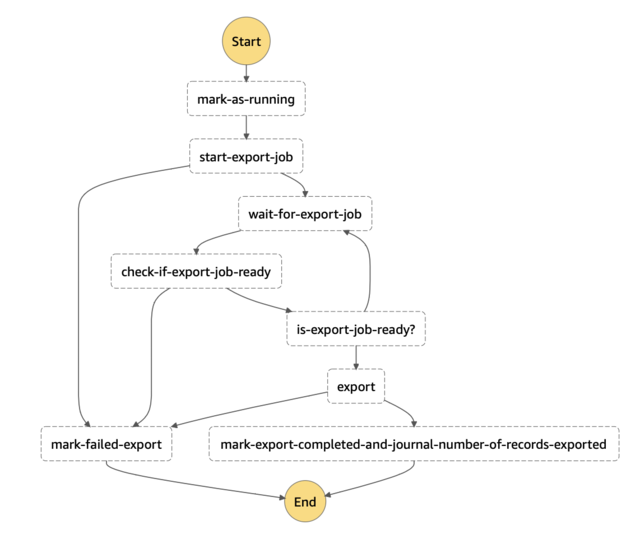
A more accurate view of our Process Batch v3.1 workflow looks like this:
Using this messaged-based architecture, we handled a growth of 400% serving a handful of Fortune 500 companies, supported by a team of only 2 backend engineers. Even so, this version still wasn't good enough. Our product was still experiencing unexpected issues every few weeks.
If only we could have finer-grained control of our workflows to account for even more state transition cases, we thought. But as you can see, even this simplistic decision diagram above is already a bit confusing even after omitting a few details including re-try limits and parallelization. Our increasing reliance on managing states between asynchronous queue workers was getting tedious and hard to manage. We were violating the 'don't repeat yourself' principle with our boilerplate operational application code and system infrastructure.
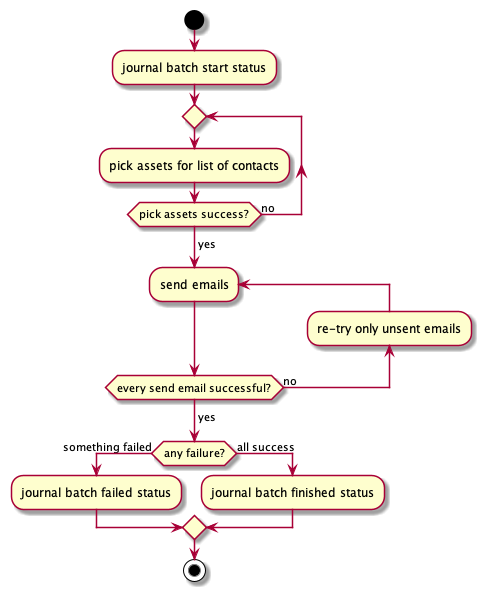
The Send Emails validation step in the above decision-flow diagram, for example, creates a decision path in our Process Batch workflow. If all emails were successfully sent, we proceed normally, but if any of the emails failed to send, we break off to an alternate path to re-try only the unsent emails. I coded this path with 2 separate workers over 2 separate queues; one paired worker and queue for the happy path, and a second pair for the failed path. Every extra decision in our workflow therefore became yet another worker and queue pair. With this naive implemenation, our need to impose finer-grained control of our workflows was becoming unmanageable.
Application Workflow Orchestration is a solved problem
What we needed was an application workflow orchestration engine. All those distinct queues we created to cover every decision path and the database journals used to keep track of step statuses are boilerplate logic for solving a known problem. Take a look at AWS Step Functions for an example of a workflow orchestration engine as a service. It's also what we ended up using for production.
AWS Step Functions is a low-code visual workflow service used to orchestrate AWS services, automate business processes, and build serverless applications. Workflows manage failures, retries, parallelization, service integrations, and observability so that developers can focus on higher-value business logic.
These feature -- manage failures, retries, ... and observability -- match the exact operational requirements that I've been building up to in this blog post and in our actual system.
It's worth pointing out that there are plenty of other workflow orchestration engines to choose from. AWS Step Functions just happens to fit our particular use cases.
Failure handling as decision paths
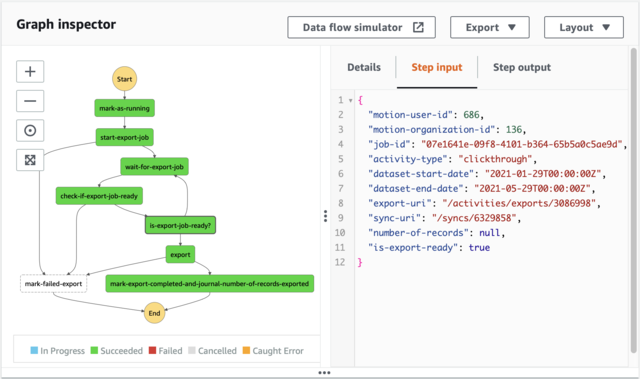
Below is a screenshot from the AWS Step Functions UI on one of our workflow definitions. Defining a workflow is simply a matter of writing a JSON definition (in our case, we use Stepwise, an open-source Clojure library on AWS Step Functions) to specify the state transition logic. All the boilerplate operational aspects, including creating implicit queues and tracking execution history (see next section), are taken care of for you. In this diagram alone, I would have needed to create 7 queues and 8 sets of status records for this workflow. I can't stress enough how the freedom from needing to explicitly create an endless number of queues and journal entries is a huge time saver!
Along with a JSON workflow definition to create this state machine, you have to assign workers to each of the steps. We simply re-used our existing workers because our system had alredy been implemented as a message-based architecture.
Once you have your workflow definition and workers assigned, Step Functions will automatically route output from one worker as input to the next according to the logic in your workflow definition. Routing options such as timeouts, re-tries, and route by output values are all available.
Monitoring 2.0: History for each execution
High-level CloudWatch metrics such as step failure counts over time are provided. These metrics are equivalent to the queue metrics mentioned previously. Moreover, Step Functions also provide a complete step-by-step history for each individual execution! This is valuable as it enables non-developer on the team to inspect particular executions for customer support.
I hope this has been a useful summary of our application business workflow management journey. In the next post, we will dive into our Stepwise library to illustrate how to set up and execute an AWS Step Functions workflow.